Die statischen Quartz-Bröckerln hochladen
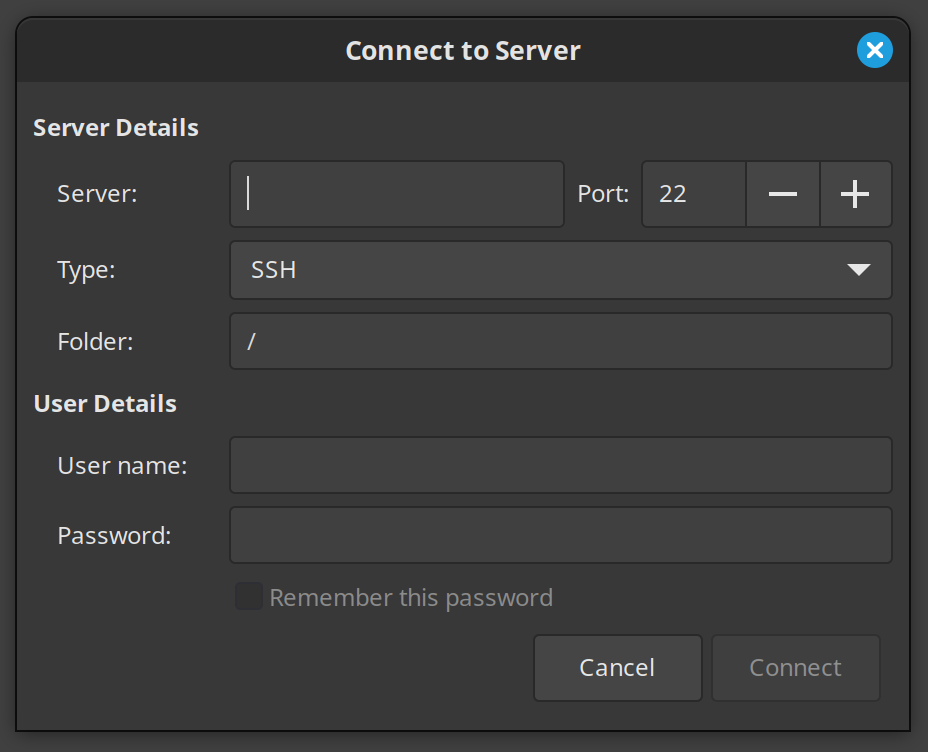
Wie im vorherigen Beitrag gezeigt, ist es relativ einfach aus simplen Markdown Notizen in Quartz eine Website zu erstellen. Diese Website ist jedoch nur auf dem jeweiligen Rechner unter localhost:8080 aufrufbar. Um die Seite auch übers Internet erreichen zu können, braucht man einen Webserver der Apache bzw. Nginx installiert hat. Das hat man im Prinzip bei jedem Webhosting-Paket dabei. Bei meinen Webhoster Netcup (soll keine Werbung sein) ist das simpel. Man verbindet sich via SSH (oder FTP) mit dem Server. Unter Linux mit Cinnamon hat man die Möglichkeit eine SSH Verbindung auch direkt über den Filebrowser Nemo herzustellen. Dazu klickt man auf ‘File’ (bei mir läuft das Betriebssystem auf englisch) und wählt ‘Connect to Server…’ und schon kann man sich mit den Anmeldedaten des jeweiligen Hosters anmelden:
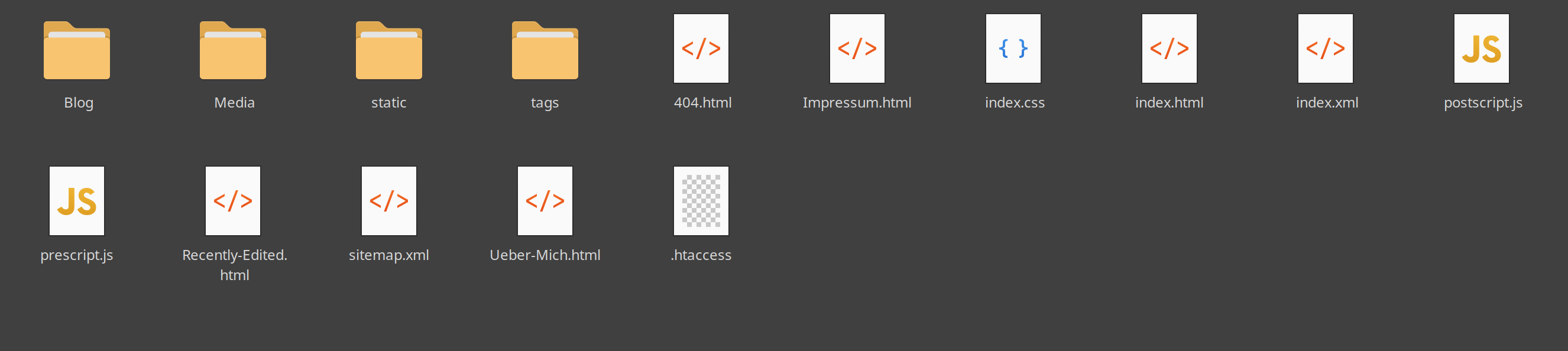
Dann navigiert man in den Ordner mit dem Namen der Domain und dort befindet sich der Ordner für die Website-Dateien, bei mir ‘httpdocs’:
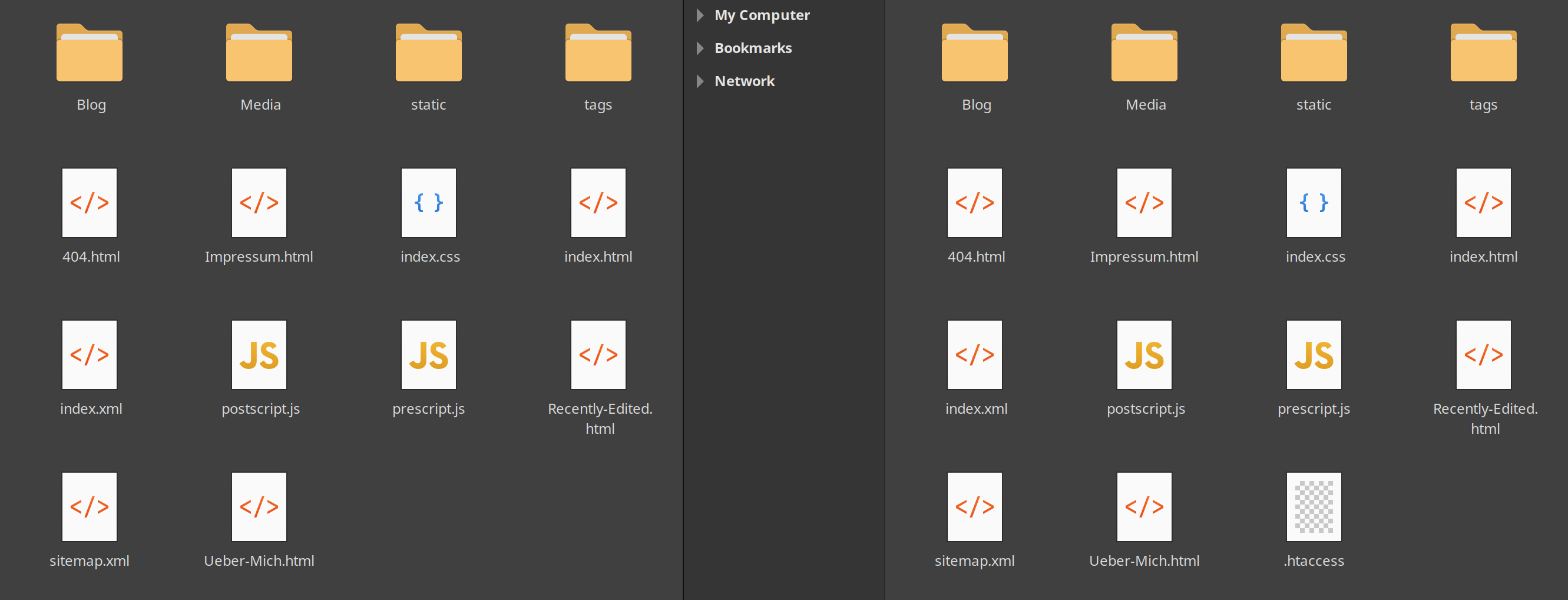
Und schon kann man den lokalen Quellordner (/quartz/public) und den Zielordner nebeneinander legen und die Website hochladen:
Bei Netcup war noch notwendig die kleine Datei ‘.htaccess’ anzulegen, diese sagt dem Webserver, dass es auch in Ordnung ist Seiten zu laden, wenn diese keine ‘.html’-Endung haben. Der Inhalt der Konfig-Datei sieht so aus:
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^([^\.]+)$ $1.html [NC,L]
robots.txt um KI-Crawling zu stoppen
Wenn man nicht möchte, dass die eigenen Texte nicht einfach so in die kommende Generation von GPT und Co. kommen sollen, dann bleibt einem nicht viel übrig. Das was man jedoch tun kann ist eine kleine Datei hochladen, die darum bittet, dass große kommerzielle Anbieter die Seite nicht für KI-Trainung zu verwenden. Laut dieser Seite ist diese robot.txt Datei zumindest ein guter Anfang:

Ich möchte dabei betonen, dass dies erstens nur ein freundliches Bitten ist und ich zweitens nichts per se gegen das Verwenden meiner Texte habe, aber die großen kommerziellen Anbieter sollen nicht einfach so Zugang zu einem noch größeren Textkorpus bekommen. Aber das ist eine größere Diskussion.
Weitere Schritte
Wem das manuelle Kopieren der Seite zu umständlich ist, der kann als einfache Variante Github Pages verwenden und dort mit den Github Actions den Hochladeprozess automatisieren. Ich werde mir jedoch noch die “Eigenbauvariante” ansehen und versuchen mit einem Skript und auf einem LXC-Container unter Proxmox diesen Prozess zu automatisieren. Wenn das nicht zuverlässig funktionieren sollte, werde ich gegebenfalls auf die Githubsche Variante zurückgreifen. Für diesen Ansatz kann ich dieses Video empfehlen (wie auch die anderen Videos zu Obsidian auf diesem Kanal). In einem der nächsten Beiträge werde ich zeigen wie man das bewerkstelligen kann.