Wäre es nicht schön?
Ich habe schon seit längerem darüber nachgedacht etwas Ordnung in meine wachsende Zahl der Beiträge für diese Seite zu bringen. Letztlich bin ich auf die Unique Identifier à la Youtube ID gekommen: Base64. An dieser Stelle habe ich bereits darüber geschrieben. Jetzt kommt der Zeitpunkt, dass ich es auch umsetze. Ich verwende Obsidian für meine Notizen und auch als eine Art Eigenbau-CMS. Für dieses Programm gibt es eine Unzahl an Community-Plugins, darunter das sog. “Custom File Explorer sorting” von “SebastianMC”, hier ist das Github-Repository. Damit kann pro Ordner eine eigens angepasste Sortierung der Notizen definieren, genau was ich brauche, um meinen Plan umzusetzen.
Herumprobieren mit Probe-Vault
Da ich meine Notizen nicht verpfuschen möchte, teste ich meine Idee an einem neuen Vault. Das geht ganz einfach, man muss nur den gewünschten Ordner wohin kopieren, dann links unten auf den eigenen Vault (hier “Obsidian” genannt) klicken…

… und auf “Manage vaults” gehen…
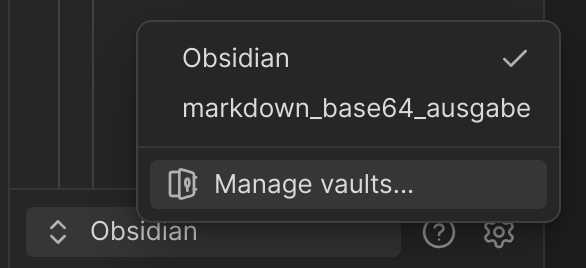
… und den neuen Ordner als Zweit-Vault aufmachen:
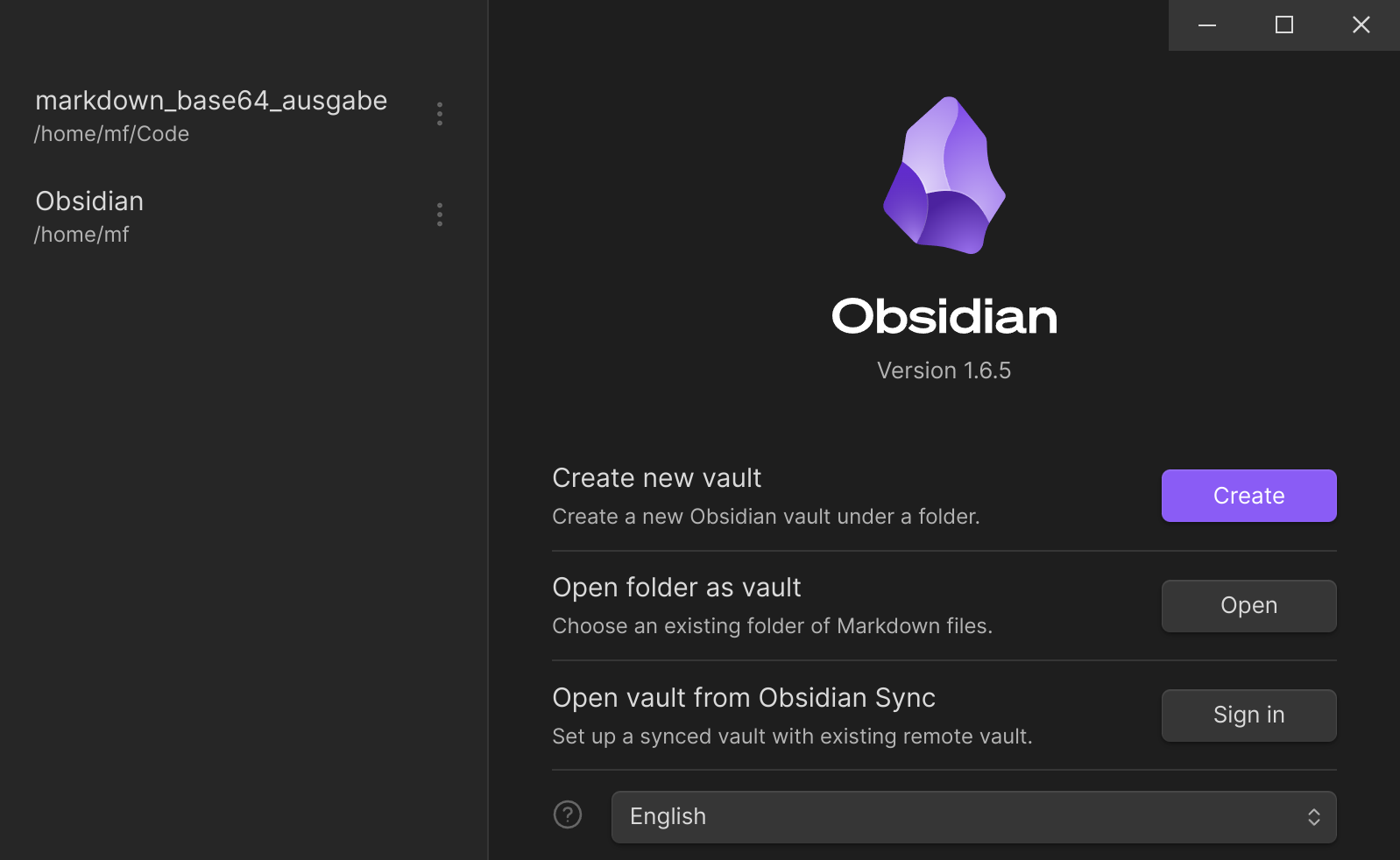
In meinem Fall nehme ich gleich den schon bestehenden Vault “markdown_base64_ausgabe” (wo nicht nur base64-benannte Testnotizen, sondern auch base36 und base62, drinnen sind).
Dort kann man die Standardsortierung für die Base64-Notizen erkennen:
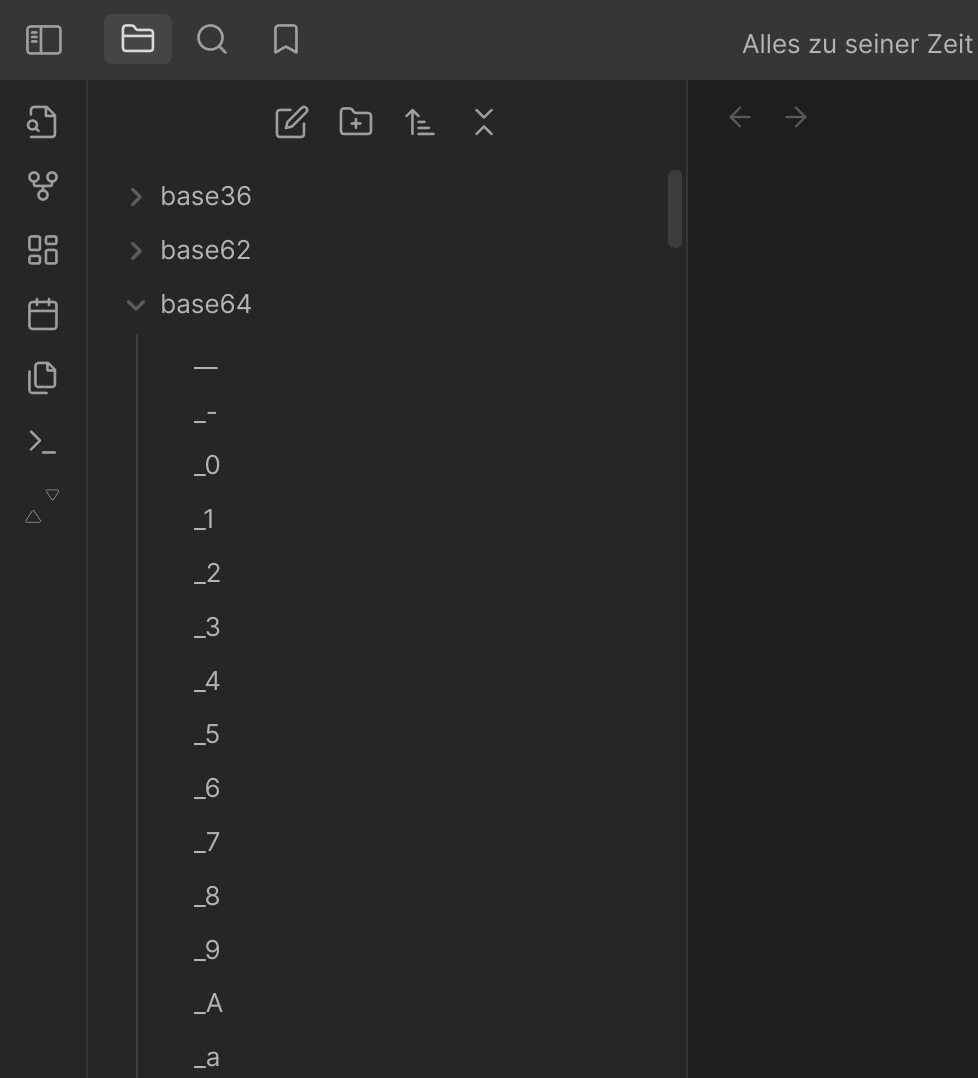
Die Reihenfolge ist nicht kongruent mit der im File Browser (Nemo 6.0.2)…
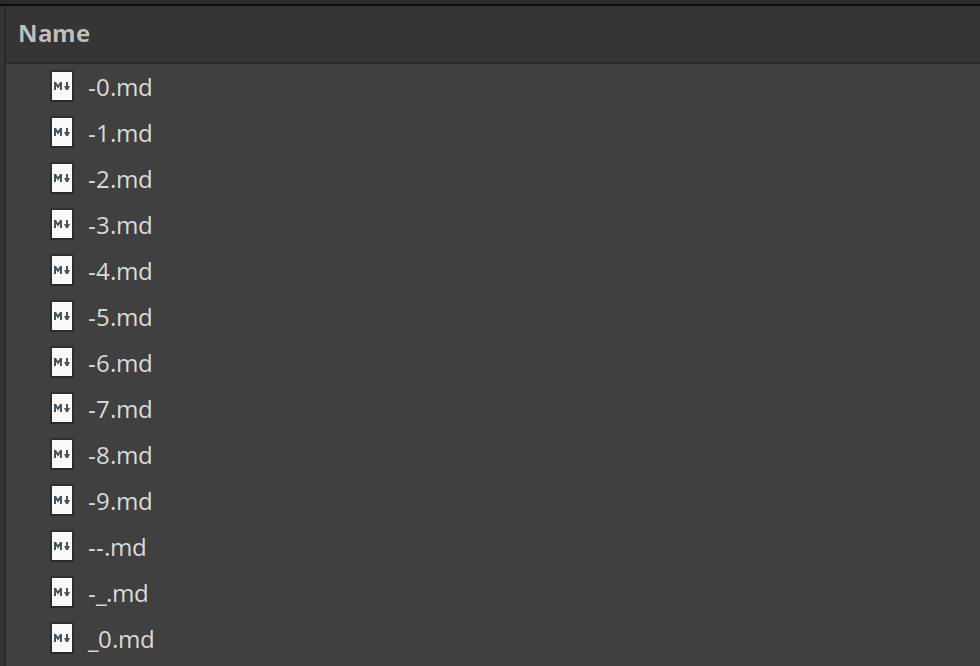
… und auch nicht mit der Sortierung, die im Terminal zu finden ist:
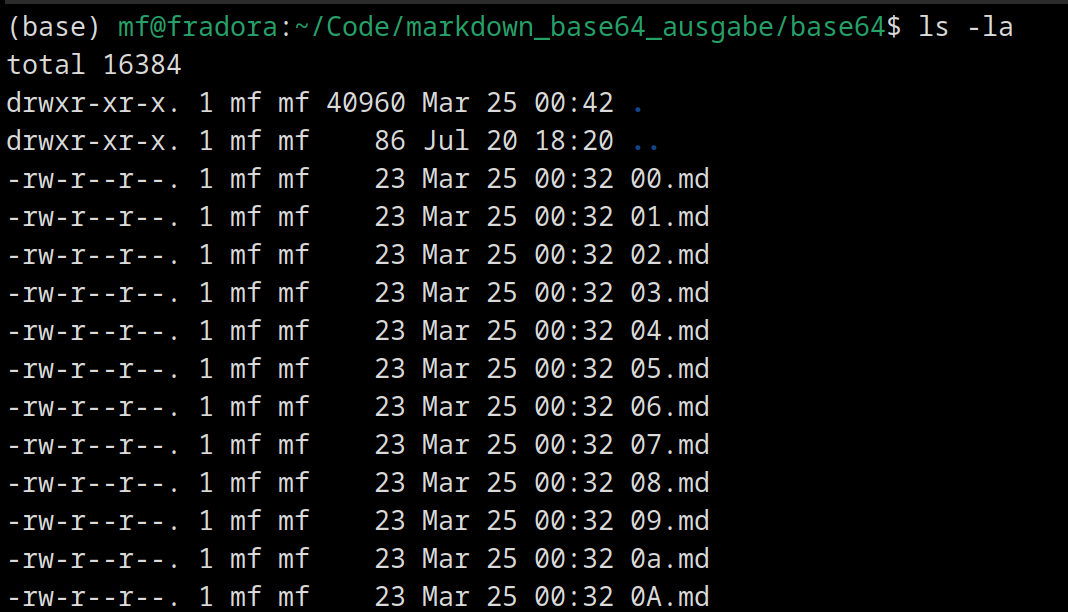
Ich würde mich lieber an die “Standard”-ASCII-Sortierung halten und versuche sie auch unter Obsidian hinzubekommen. Für das oben genannte Sortierungs-Plugin muss man im zu sortierenden Ordner eine Notiz namens “sortspec” erstellen,
Dazu brauchen wir geht mit dem folgenden YAML-Codeblock (aus der Dokumentation):
---
sorting-spec: |
order-asc: true a-z
---Und das sieht dann so aus:
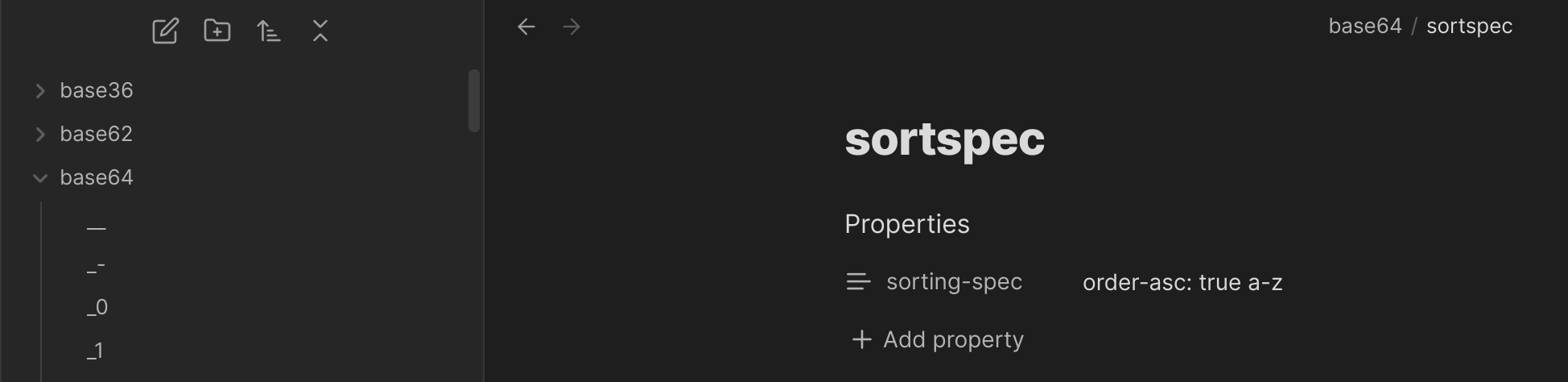
Anschließend muss man noch die neue Sortierung anstoßen:
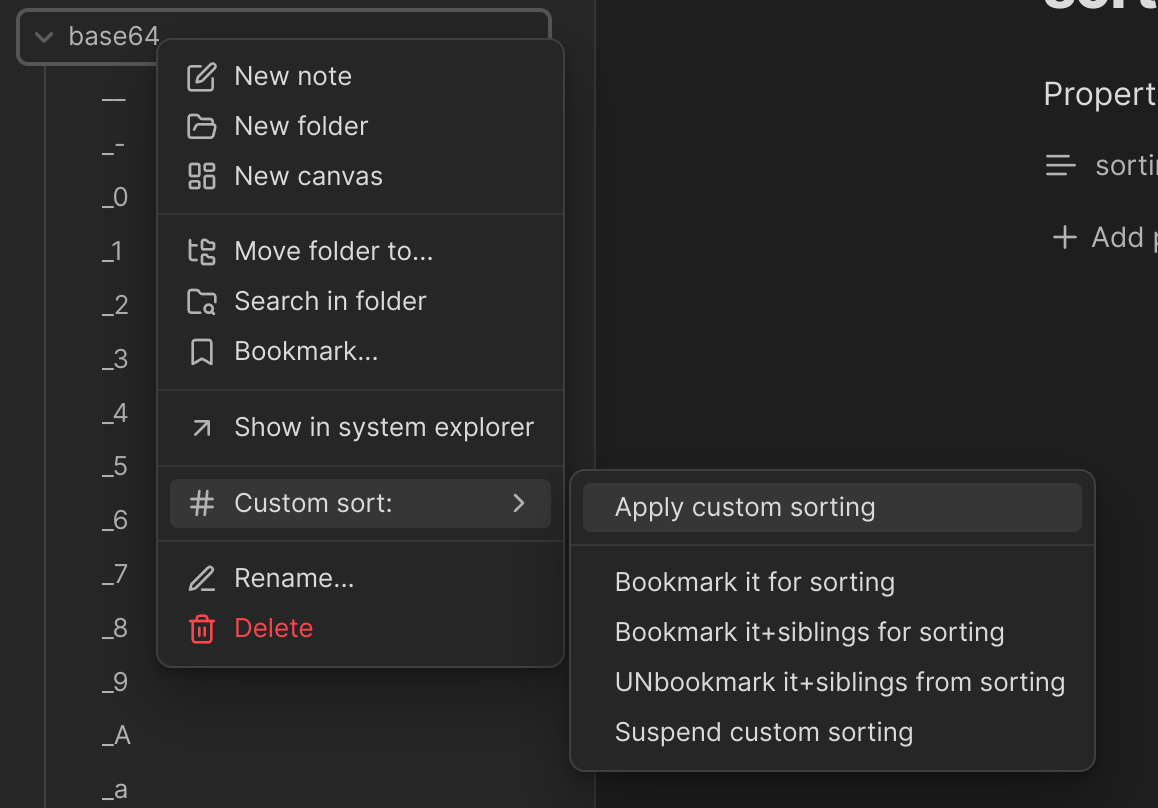
Und es tut nichts. Naja, das war es wohl nicht. Die URL-freundliche Variante von Base64 sollte eigentlich so sortieren:
-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz
Die Lösung könnte in der erweiterten ReadMe von “SebastianMC” stehen:
---
sorting-spec: |
target-folder: /
Pro...
A...s
Res...es
...ive
---
Ich habe diese Sortierung auf ASCII vom Chatbot ummodeln lassen:
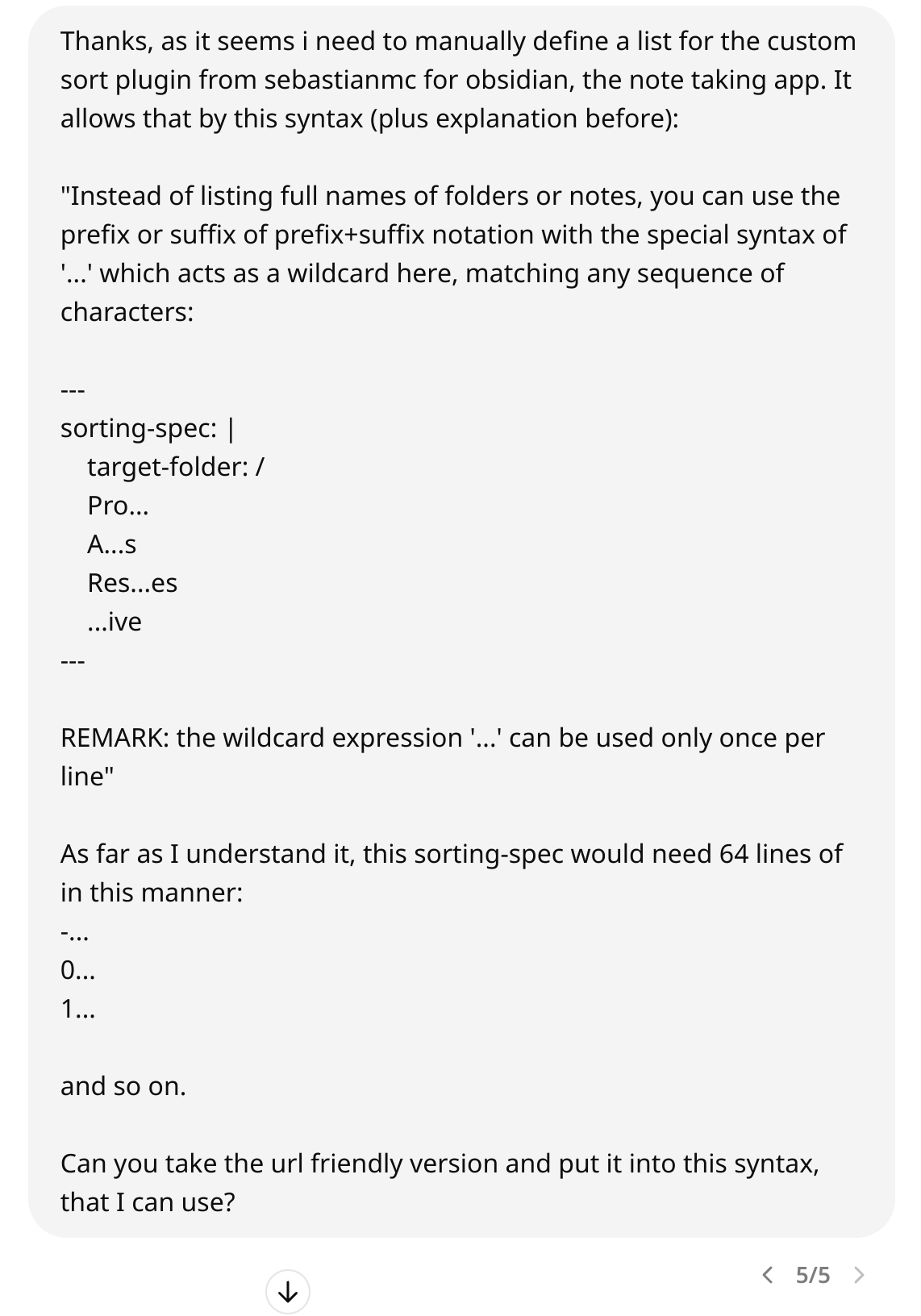
Und das Sprachmodell hat diese Syntax ausgespuckt:
sorting-spec: |
target-folder: /
-...
0...
1...
2...
3...
4...
5...
6...
7...
8...
9...
A...
B...
C...
D...
E...
F...
G...
H...
I...
J...
K...
L...
M...
N...
O...
P...
Q...
R...
S...
T...
U...
V...
W...
X...
Y...
Z...
_...
a...
b...
c...
d...
e...
f...
g...
h...
i...
j...
k...
l...
m...
n...
o...
p...
q...
r...
s...
t...
u...
v...
w...
x...
y...
z...
Um das komfortabel in Obsidian einfügen zu können, ist es besser den Source Mode zu aktivieren:
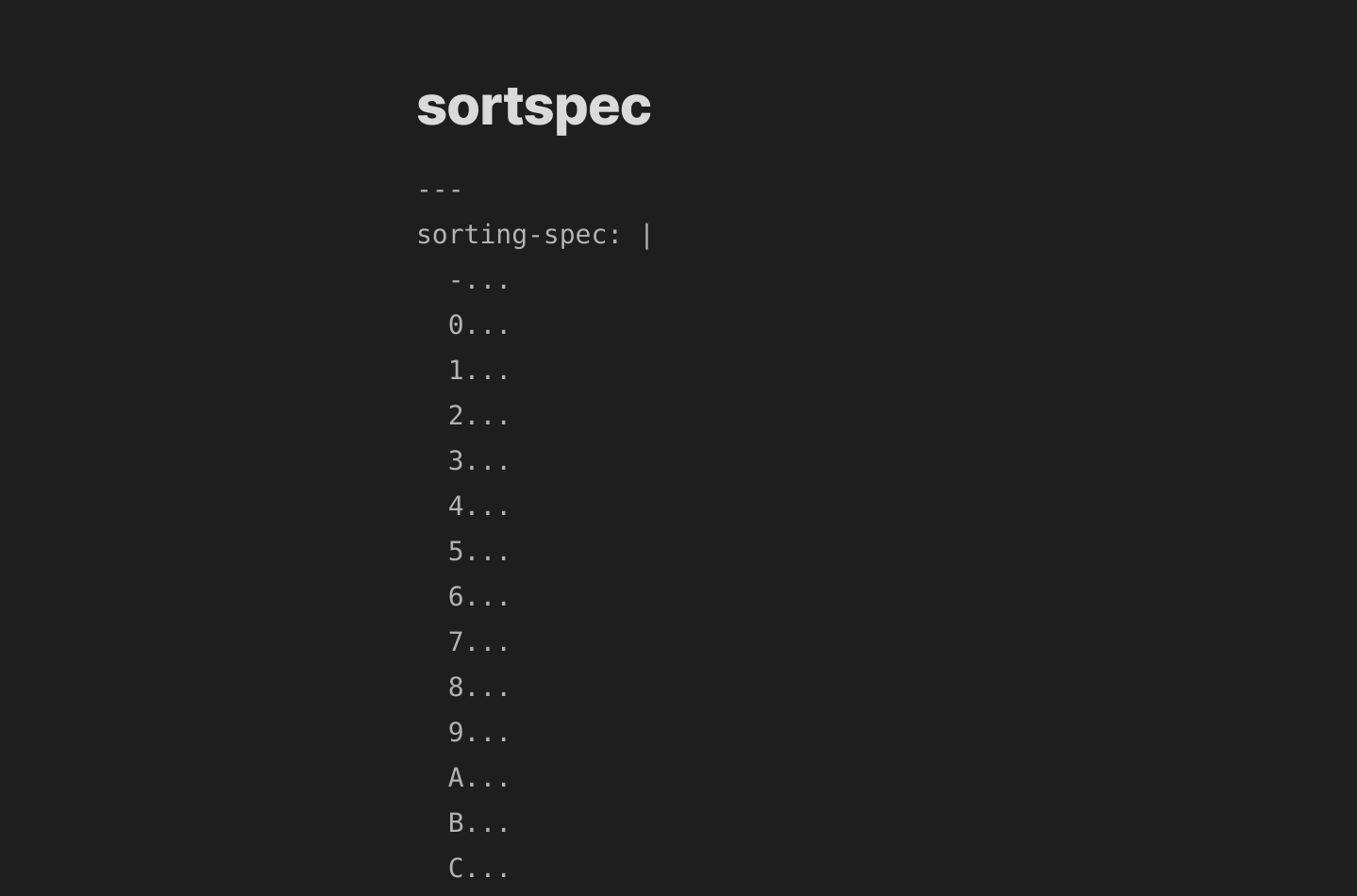
Und so schaut sortspec in Obsidian dann aus…
… und bei den Notizen selbst…
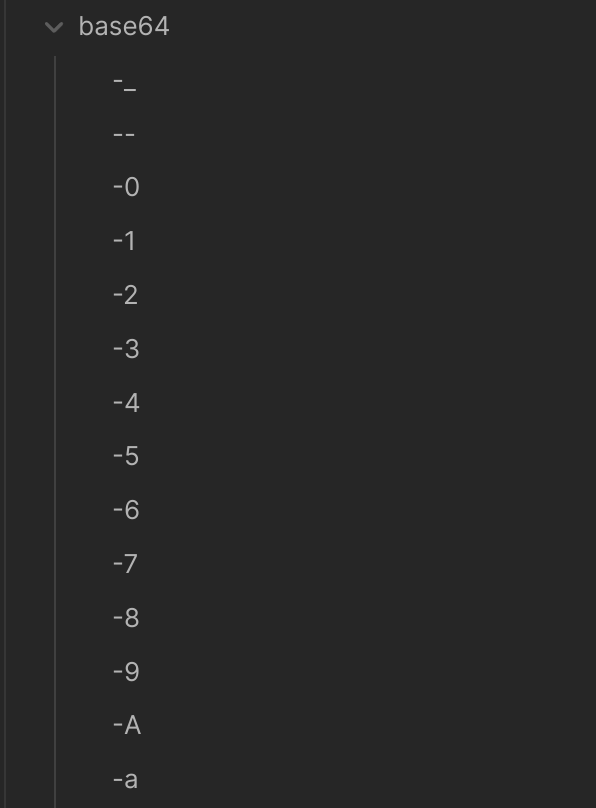
… fast ein Erfolg. Leider sortiert das halt nur in der vordersten Stelle korrekt. Naja, das passt letztlich auch wieder nicht. Ich glaube ich versuhe es noch einmal mit base62…
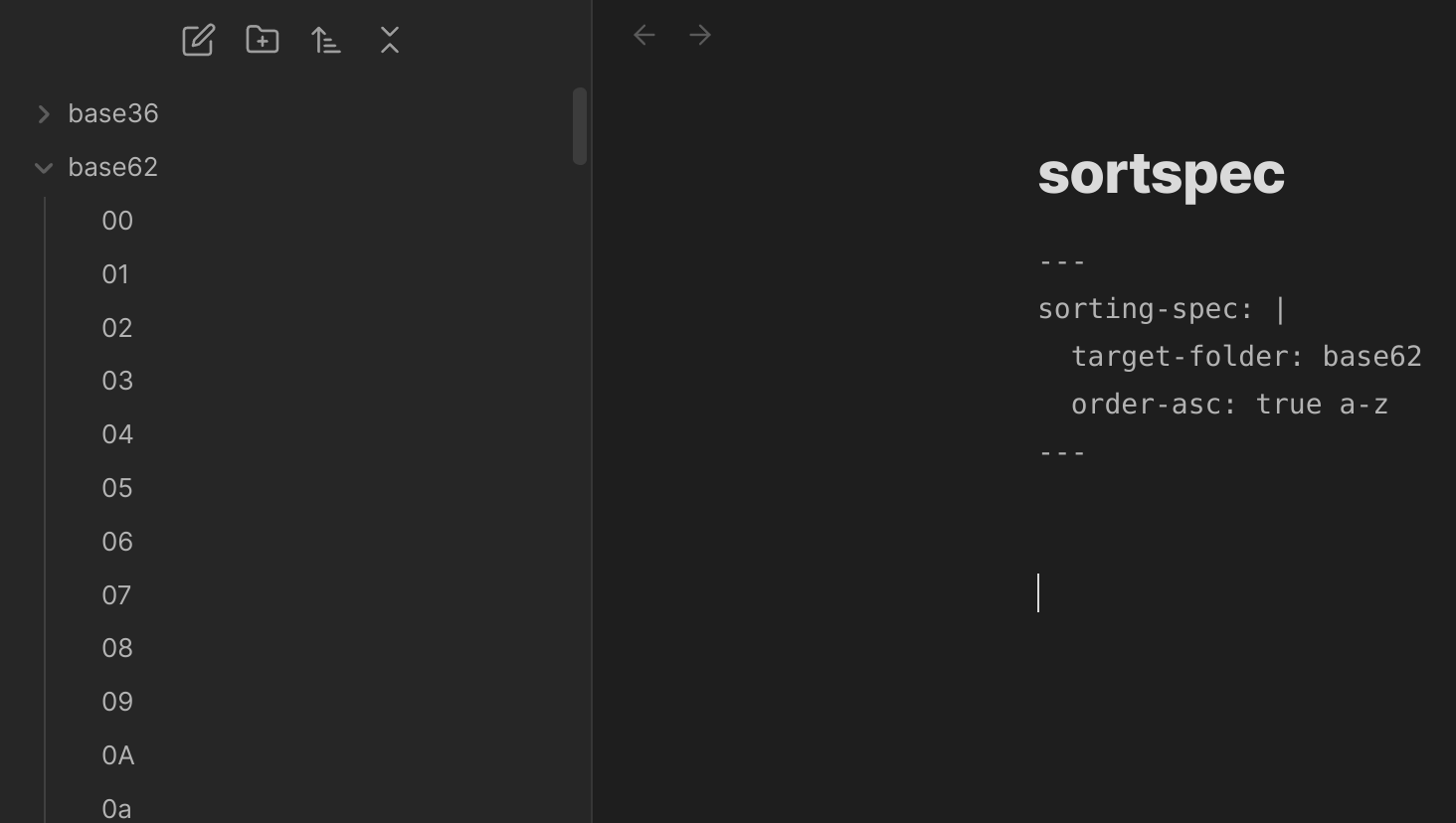
… die Sortierung ist leider nach wie vor nicht konsequent.
Erfolg mit vsc-unicode
Mit der vsc-unicode[¹] Sortierung (order-desc: vsc-unicode), scheint es jedoch zu gehen. Im folgenden Screenshot sieht man, von unten nach oben gelesen, dass an erster Stelle zuerst ein Minus (”-”) zu sehen ist:
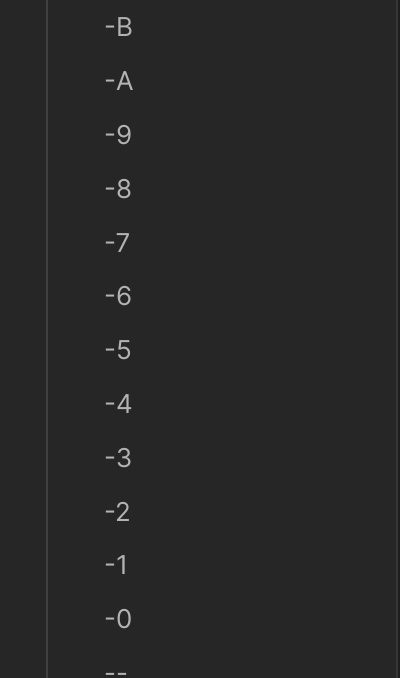
An der zweiten Stelle sieht man, dass danach die Zahl folgt und anschließend Großbuchstaben kommen.
Hier sieht man dann, dass, wieder an erster Stelle, dass nach den Großbuchstaben der Unterstrich (”_”) und an der zweiten Stelle, der Buchstabe “z” als Kleinbuchstabe als letzter kommt:

Somit haben wir endlich eine mehr oder weniger standardisierte Methode, wo die jeweiligen ASCII-Zahlenwerte die Reihenfolge der base64-Sortierung vorgeben. Im nächsten Beitrag versuche ich ein tatsächliches Setup auf die Beine zu stellen.
[¹]: Die Bezeichnung “unicode” passt hier nicht ganz, wie man anhand der Ausführungen des Github-Repo-Betreibers sehen kann: “I tried to find the rationale behind the why the name ‘unicode’ was used in VS, I scanned some of discussions like this for more background. It looks like an arbitrary decision motivated by an intent to keep the label short. Even the UI hint which VSC displays ‘Names are sorted in Unicode order’ is ambiguous, if one is aware of the complexity behind unicode (‘Is this by Unicode character codes order or by Unicode collation order?’)“. Unicode macht noch viel mehr, vgl. diesen Report (auch im Issue verlinkt).