O, Du Einzigartige!
Die Überlegung zur Erstellung zweier Beiträge an einem Tag und wie diese sortiert werden, haben mich auf einen Gedanken gebracht. Ich könnte zwei Fliegen mit einer Klappe schlagen, wenn ich vor jeder Notiz und damit vor jedem Beitrag (oder genauer vor jeder HTML-Ausgabedatei) einen unique identifier setze. Das selbe Prinzip verwendet auch Youtube mit seinen 11-stelligen Youtube Video IDs. Nur in meinem Fall würde ich auch gerne die Notizen in Obsidian sortiert haben. Denn schon jetzt wird es ein bisserl unübersichtlich, wenn ich eine Notiz suche, da sie nach Anfangsbuchstaben sortiert werden. Nach Änderungsdatum zu sortieren ist auch keine Lösung, weil dann jede Änderung an einer alten Notiz diese nach vor reihen würde. Ein Datumsstempel (YYYY-MM-DD) würde das zwar lösen, schaut aber ein wenig unübersichtlich aus und wäre dann auch wieder nicht einzigartig (außer ich schreibe nur maximal einen Beitrag am Tag). Deswegen habe ich mir gedacht ich könnte die base64-Codierung von Youtube kapern, um meine Notizen zu sortieren und auch eine Art Permalink für die Website zu haben (weil ich sonst mit jeder nachträglichen Namensänderung potenziellen link rot produzieren würde). Mit nur zwei Zeichen als Präfix ergeben sich schon 4096 Beiträge! Dadurch hätte ich die Einzigartigkeit pro Beitrag und Sortierung in Obsidian. Zumindest habe ich mir das gedacht.
Herumspielen mit GPT-4 und Python
Vor der Revolution mit den Sprachmodellen hätte ich es wohl an dieser Stelle belassen. Viel zu kompliziert, da bräucht’ ich ja Tage, wenn nicht Wochen, um irgendwas Brauchbares rauszubekommen. Aber seit es Sprachmodelle wie GPT-3 und noch viel mehr GPT-4 gibt (und die lokal laufenden Modelle werden auch immer besser) sind solche Projekte auch für interessierte Laien möglich geworden.
Frage an den Chatbot
Also beginnt erst einmal alles mit einer Frage an den Chatbot:
Would it be possible to use some kind of semi manual use of base64 (a la youtube video id), but only with two digits (giving a range of 4096 posts) which would be simply at the beginning of each entry name. But there I have the question, does base64 (in its yt variant of using - and _) sort alphabetically, because that would have the handy side effect, that all my notes in obsidian would be sorted automatically as well.
Die Antwort:

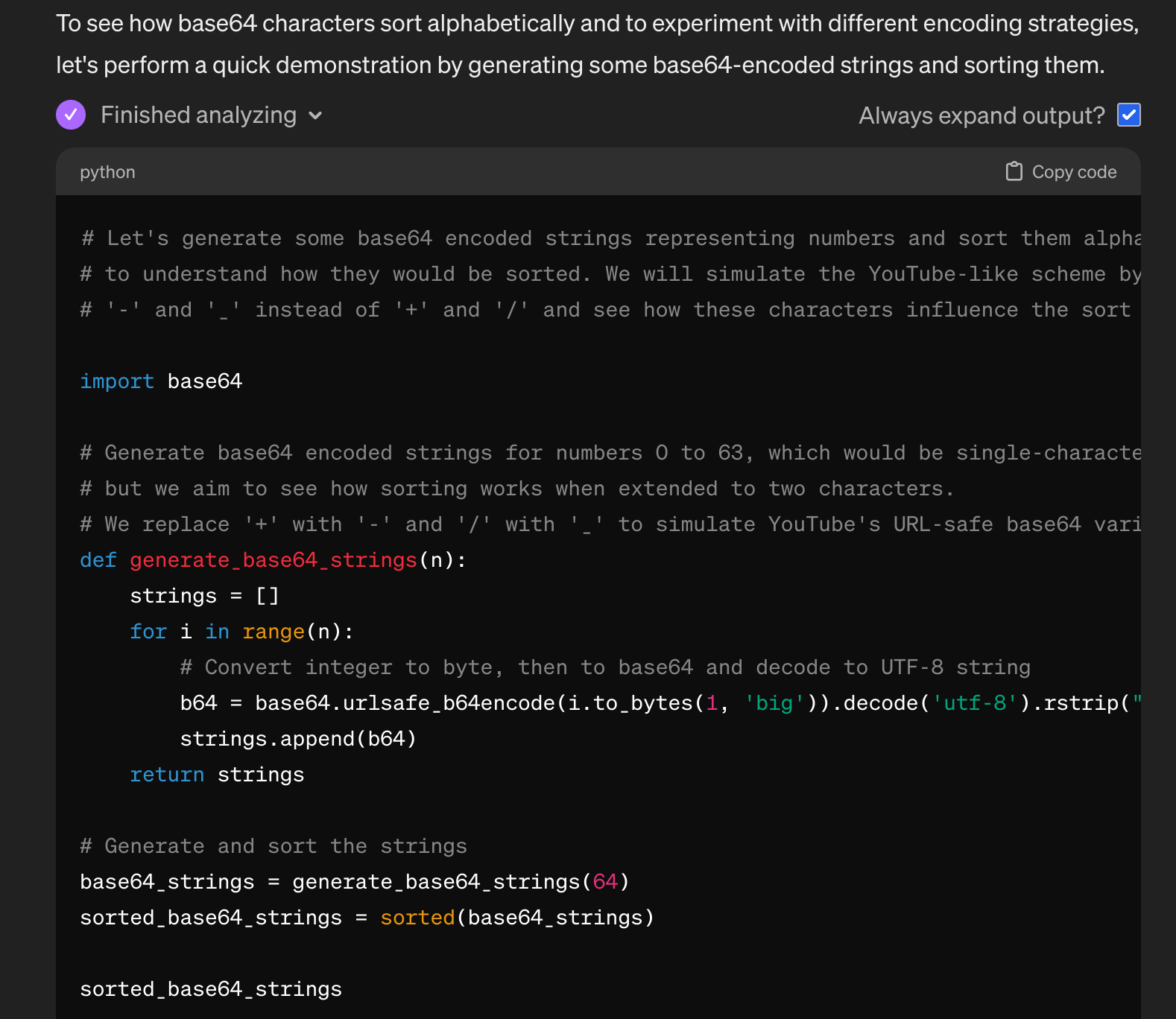
Einerseits finde ich es nach wie vor faszinierend, wie gut die Antworten von GPT-4 sind, andererseits macht das dargebotene Skript, wie es mit Sprachmodellen jedoch oft so ist, nicht was man will. Erst nach ein paar mal hin und her und noch viel wichtiger, dem freigiebig anzuwendenden Bearbeitenknopf (dazu sollte ich auch einmal einen Beitrag schreiben) …


…

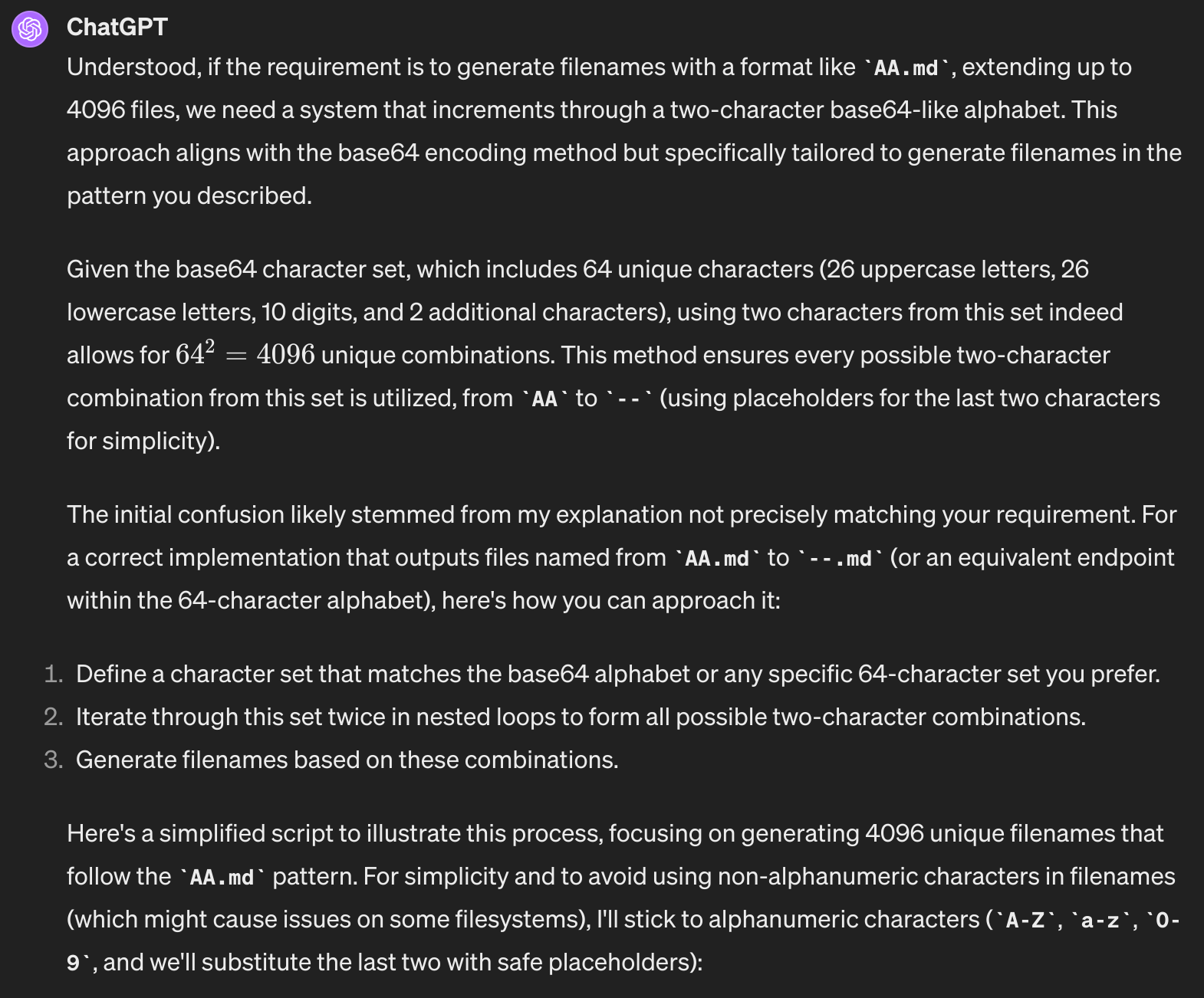
… bekommt man auch ein Skript das genau das tut was es soll, nämlich tausende Probenotizen in Windeseile erstellen:
import os
def generate_base64_filenames(directory, total_files=4096):
# Define a base64-like alphabet (using 'X' and 'Y' as placeholders for '+', '/')
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789XY'
# Ensure the output directory exists
os.makedirs(directory, exist_ok=True)
# Initialize file count
file_count = 0
# Generate filenames
for first_char in alphabet:
for second_char in alphabet:
filename = f"{first_char}{second_char}.md"
file_path = os.path.join(directory, filename)
with open(file_path, "w") as file:
file.write(f"# {filename[:-3]}\n\nContent for {filename}")
file_count += 1
if file_count >= total_files:
return
# Example usage
output_directory = "path/to/your/output/directory" # Change this to your desired path
generate_base64_filenames(output_directory)
So macht programmieren auch einem nicht-Programmierer wie mir Spaß.
Das Skript selbst ist sehr simpel und ich lade auch zum selbst herumprobieren ein. Hier meine Anpassungen:
import os
def generate_base64_filenames(directory, total_files=4096):
# Define a base64-like alphabet (using 'X' and 'Y' as placeholders for '+', '/')
alphabet = 'abcdefghijklmnopqrstuvwxyz0123456789' # base36
# alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_' # base64
# alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789' # base62
# Ensure the output directory exists
os.makedirs(directory, exist_ok=True)
# Initialize file count
file_count = 0
# Generate filenames
for first_char in alphabet:
for second_char in alphabet:
filename = f"{first_char}{second_char}.md"
file_path = os.path.join(directory, filename)
with open(file_path, "w") as file:
file.write(f"# {filename[:-3]}\n\nContent for {filename}")
file_count += 1
if file_count >= total_files:
return
# Example usage
output_directory = "markdown_base64_ausgabe" # Change this to your desired path
generate_base64_filenames(output_directory)Die ersten Tests mit base64 haben sich sogleich als problematisch erwiesen. Im Dateibrowser, in Obsidian und im Terminal wurde jeweils anders sortiert! Vor allem - und _ werden irgendwie sortiert. So bringt das eher weniger, wenn es keine konsistente Sortierung gibt.
Geht’s auch eine Spur kleiner? Das Problem mit der Sortierung
Die nächste Überlegung: wer braucht schon die Basis 64? Wir können doch auch base62 nehmen. Dann sind’s halt nur mehr 3844 Beiträge, aber das reicht doch auch. Naja, die Groß- und Kleinbuchstaben werden wieder in Obsidian und im Filebrowser unterschiedlich sortiert. Letzte Idee: Was ist mit base36? Also nur Kleinbuchstaben und Zahlen. Ja, das sortiert konsistenter, dann sind’s aber nur mehr 1296 Beiträge. Aber auch hier gibt es Inkonsistenzen.
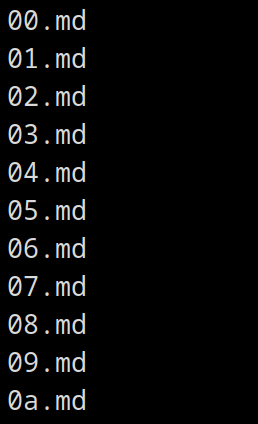
Im Terminal schön UNIX-artig:
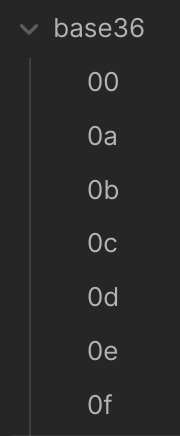
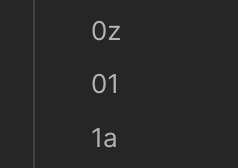
In Obsidian:
…
…

Diese Diskrepanz ergibt sich durch die Unterschiede bei der klassischen alphanumerischen Sortierung und der “natürlichen” Sortierung, in diesem Beitrag moniert das ein Nutzer im Forum von Obsidian. Die Lösung dafür ist das Plugin Custom Sort. Das bietet aber noch viele weitere Möglichkeiten und das werde ich mir in Ruhe ansehen.
Prinzipielles
Außerdem beschleicht mich das Gefühl, dass nicht nur die prinzipielle alphanumerische Sortierbarkeit, sobald man ein komplettes Set hat, wichtig ist, sondern, dass auch der Code bereits on the fly die jeweils nächste ID in der richtigen Reihenfolge ausspucken sollte. Andernfall muss das ganze Set wohl in voller Länge vorhanden sein, um als Referenz zu dienen. Da gibt es noch Potenzial für Überlegungen.
Aber das Gute daran: ich hab etwas zu Sortierung, base64 und Python gelernt, außerdem war es eine witzige Übung – es hat auch was ein Skript ausführen und im Bruchteil einer Sekunde hat man abertausende neue Dateien im Ordner liegen. Und das ist ja das Wichtigste bei solchen Unterfangen.