Aus Ton wird Text
Maschinelle Transkription, also das automatische niederschreiben von Gesagtem ist eine praktische wie revolutionäre Sache. Ich verwende schon seit längerem Whisper und dessen Erweiterung WhisperX im privaten und beruflichen Umfeld. Dieses Werkzeug hat im Windschatten des großen KI-Hypes einiges umgekrempelt, ohne, dass es dem breiten Publikum bekannt wäre. Automatische Spracherkennung (oder auf englisch ASR – automatic speech recognition) hat bis vor Whisper nie wirklich zuverlässig genug funktioniert. Die Tonqualität musste sehr gut sein und wehe es wurde zu sehr in Umgangsprache oder gar Dialekt gesprochen, dann ging gar nichts mehr. Seit Whisper ist das anders. Es transkribiert sogar autochthone, südlich des Weißwurst-Äquators entstandene Aufnahmen, wenn auch mit einer gewissen Tendenz zur Standardisierung des Gesagten (mehr siehe unten).
Ich nutze normalerweise eine Grafikkarte, um eine schnelle Transkription zu ermöglichen. Das ist aber nicht notwendig, wenn Geschwindigkeit nicht der ausschlaggebende Faktor ist. In diesem Beitrag werde ich beschreiben, wie man WhisperX auch in einem kleinen LXC Container unter Proxmox zum Laufen bringt, ganz ohne GPU.
Proxmox Setup
Da ich sowieso einen kleinen Heimserver mit Proxmox habe, installiere ich WhisperX auf auf einen solchen. Wenn man das einfach so auf dem eigenen Rechner oder Laptop probieren will, ist das auch kein Problem, aber es braucht halt entweder ein Linux oder unter Windows auch Linux nur halt mit WSL.
Unter Proxmox setze ich einfach einen LXC Container mit aktuellem Ubuntu 24.04 auf, gebe 16 GB RAM, 4 Kerne und 32 GB lokalen Speicherplatz frei:
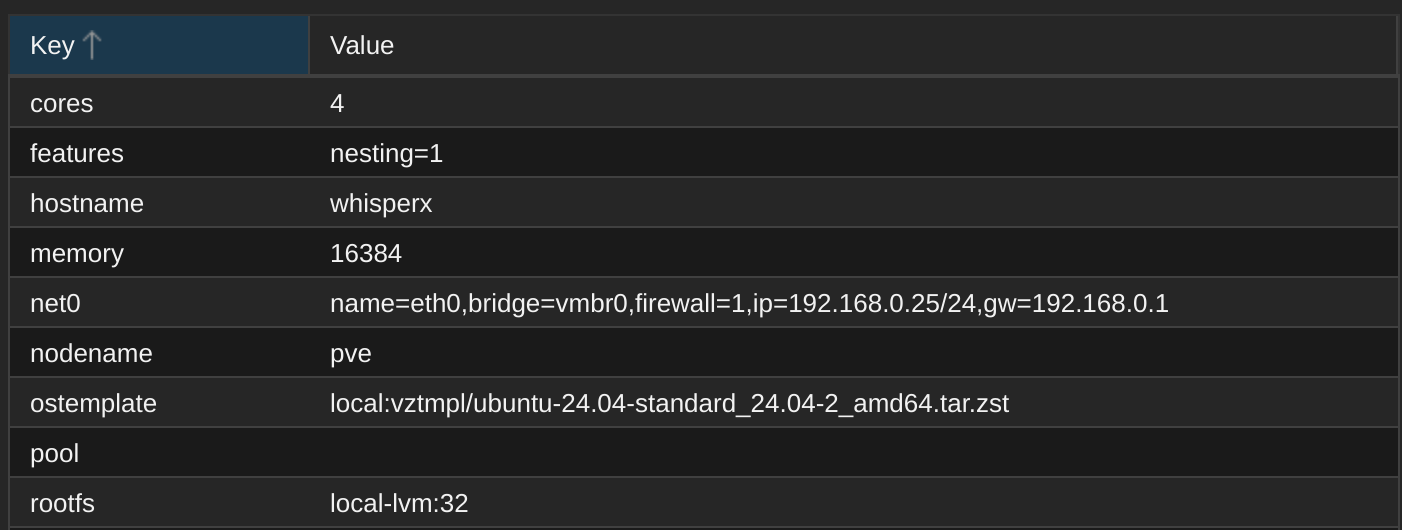
Den Container starten und die Konsole starten, oder via ssh vom eigenen Rechner aus verbinden.
Dort Updates einspielen:
apt update && apt upgradeUnd Benutzer hinzufügen:
adduser whisperxuserPasswort eingeben, andere Infos sind nicht notwendig, einfach mit Enter bestätigen:
User zur sudo Gruppe hinzufügen (oder den sudo Befehl unten als root ausführen und dann erst zum whisperxuser, dann braucht der User gar keine erhöhten Rechte, was aus Sicherheitsperspektive zu bevorzugen ist. Ich habe am Ende die den User wieder aus der sudo Gruppe entfernt.):
usermod -aG sudo whisperxuserUnd zum User wechseln:
su - whisperxuserDann notwendige Pakete installieren:
sudo apt install -y python3 python3-venv python3-pip ffmpeg git build-essentialDas kann dann schon ein bisschen dauern um die 322 (!) Pakete zu installieren:
{...}
0 upgraded, 322 newly installed, 0 to remove and 0 not upgraded.
Need to get 278 MB of archives.
After this operation, 982 MB of additional disk space will be used.
{...}Virtuelle Umgebung erstellen
Jetzt müssen wir eine virtuelle Umgebung erstellen. Die offizielle Anleitung von WhisperX nutzt conda, aber das wird nicht unbedingt benötigt und mit dem leichtfüßigeren venv geht es auch.
Zuerst einen Ordner erstellen – der Name ist dabei beliebig – hineinwechseln und die virtuelle Umgebung starten:
mkdir whisperx
cd whisperx
python3 -m venv venv
source venv/bin/activateSehr schön, wir haben nun eine virtuelle Umgebung aktiv, erkennbar an (venv) am Beginn der Promptzeile:

NumPy, PyTorch und WhisperX installieren
Nachtrag: Falls jemand mein exaktes Setup kopieren möchte, einmal runterscrollen zum Ende des Beitrag, requirements.txtDatei im whisperx-Ordner speichern und stattdessen einfach diesen Befehl ausführen:
pip install -r requirements.txt
Alternativ einfach die folgenden Befehle ausführen, das ist die Schritt-für-Schritt-Variante.
Da Ende März 2025 die neue Version von NumPy Version 2 noch nicht unterstützt wird, stellen wir zuerst sicher, dass NumPy nicht installiert ist (sollte es eh nicht sein) und installieren dann die letzte unterstützte Version 1.26.4 mit:
pip uninstall numpy
pip install numpy==1.26.4Jetzt installieren wir die CPU-Version von PyTorch:
pip install torch==2.2.2+cpu torchaudio==2.2.2 --extra-index-url https://download.pytorch.org/whl/cpuDie Installation lädt Einiges runter und rattert dahin:
Jetzt kommen wir zum letzten Teil der Installation, WhisperX selbst. Dafür gibt es ein eigenes Python Paket welches man mit diesem Befehl installieren kann:
pip install whisperxDas dauert dann wieder eine gewisse Zeit und produziert große Mengen an Konsolenausgaben:
Wenn es zu keinen Fehlern kommt (und bei mir war es die Ende März 2025 nicht funktionieren Version 2 von NumPy) dann läuft bereits WhisperX!
WhisperX testen
Jetzt kann man zu testen beginnen. Nachdem ich Linux Cinnamon als Desktop Umgebung verwende, nutze ich die “Connect to Server” Funktion von Nemo, dem Standarddateiexplorer, aber es funktioniert genauso mit WinSCP oder dem guten alten (wenn auch nicht immer ganz verständlichen) scp-Befehl. Nachdem ich das Testvideo hochgeladen habe, kann man mit diesem Befehl das Transkribieren beginnen:
whisperx /pfad/zur/mediendatei.endung --compute_type int8 --model large-v3Bei mir ein Ausschnitt aus der Berichterstattung zum Hochwasser im September 2024…

… und man sieht das große Modell (large-v3) von Whisper ist 3,09 GB groß.
Das Ergebnis dieses Versuches war sehr gut, auch wenn man Zeuge des üblichen Glättens und ver-Hochdeutschens wird:
Hier gilt Zivilschutzalarm.
Die Bevölkerung wird aufgerufen, zu Hause zu bleiben und die Keller nicht zu betreten.
Geh raus aus dem Keller, Alter!
Ja, weil du uns ansaufst, wenn das Wasser kommt.
Achja und es geht beim Hochwasser um’s Absaufen, nicht Ansaufen. Interessant, wenn man sich den Satz des Feuerwehrmannes genauer anschaut, denn er sagt “Geh aussa ausm Keller, Oida” und Whisper macht daraus zwar verständliches Standarddeutsch aber ändert den Satz dafür recht umfassend ab.
Im Sinne der Wissenserweiterung, hier der Ausschnitt mit eingefügten Untertiteln:
Fazit
Die CPU Version ist nicht schnell. Ohne Download des Modells, aber frisch in den Arbeitsspeicher geladen, hat die Transkription des 13 Sekunden Clips ca. 35 Sekunden benötigt. Allerdings wurde mit der Transkription selbst erst nach ca. 10 Sekunden begonnen. Das heißt wiederum mit den vier zugewiesenen Prozessorkernen einer Intel CPU der achten Generation kommt man mit dem größten Modell auf etwa halbe “Echtzeitgeschwindigkeit”. Nicht überragend schnell, aber für viele zeitunkritische Anwendungen kein Problem. Eine Nvidia RTX 3060 schafft hingegen 25-30 (!) fache “Echtzeitgeschwindigkeit”, sprich ein einstündiges Video wird in weniger als drei Minuten transkribiert. Hier würde es eher zwei Stunden dauern. Dafür kann ich diesen kleinen Container einfach durchgehend laufen lassen und einen PC mit Grafikkarte würde ich für den Hausgebrauch eher nicht 24 Stunden durchlaufen lassen wollen.
Was mache ich nun mit diesem kleinen aber geschickten Setup? Wir werden es im nächsten Beitrag sehen!
Nachtrag
Nach ein paar weiteren Tests und Rückmeldung zum Beitrag: Der Arbeitsspeicherbedarf ist auch sehr moderat mit knapp über 3 unter 7 GB (für den kurzen Clip waren es nur drei, bei einem längerem Video ging es dann Richtung 7), wenn transkribiert wird und wenn nichts läuft dann sind es nur etwas über 200 MB. Somit sollte das Werkl sogar auf meinem Mietserver laufen. Weiters habe ich den Hinweis bekommen, dass die sudo Rechte für den whisperxuser gar nicht notwendig sind und für einen Service-Account auch nicht empfehlenswert (siehe Principle of Least Privilege). Mit diesem Befehl entfernt man die sudo Rechte wieder vom User:
sudo deluser whisperxuser sudoFür das einfachere Nachinstallieren kann man den folgenden Text auch als requirements.txt speichern und oben statt den anderen pip Befehlen ausführen.
aiohappyeyeballs==2.6.1
aiohttp==3.11.14
aiosignal==1.3.2
alembic==1.15.2
antlr4-python3-runtime==4.9.3
asteroid-filterbanks==0.4.0
attrs==25.3.0
av==14.2.0
certifi==2025.1.31
cffi==1.17.1
charset-normalizer==3.4.1
click==8.1.8
coloredlogs==15.0.1
colorlog==6.9.0
contourpy==1.3.1
ctranslate2==4.4.0
cycler==0.12.1
docopt==0.6.2
einops==0.8.1
faster-whisper==1.1.0
filelock==3.18.0
flatbuffers==25.2.10
fonttools==4.56.0
frozenlist==1.5.0
fsspec==2025.3.0
greenlet==3.1.1
huggingface-hub==0.29.3
humanfriendly==10.0
HyperPyYAML==1.2.2
idna==3.10
Jinja2==3.1.6
joblib==1.4.2
julius==0.2.7
kiwisolver==1.4.8
lightning==2.5.1
lightning-utilities==0.14.2
Mako==1.3.9
markdown-it-py==3.0.0
MarkupSafe==3.0.2
matplotlib==3.10.1
mdurl==0.1.2
mpmath==1.3.0
multidict==6.2.0
networkx==3.4.2
nltk==3.9.1
numpy==1.26.4
omegaconf==2.3.0
onnxruntime==1.21.0
optuna==4.2.1
packaging==24.2
pandas==2.2.3
pillow==11.1.0
primePy==1.3
propcache==0.3.1
protobuf==6.30.2
pyannote.audio==3.3.2
pyannote.core==5.0.0
pyannote.database==5.1.3
pyannote.metrics==3.2.1
pyannote.pipeline==3.0.1
pycparser==2.22
Pygments==2.19.1
pyparsing==3.2.3
python-dateutil==2.9.0.post0
pytorch-lightning==2.5.1
pytorch-metric-learning==2.8.1
pytz==2025.2
PyYAML==6.0.2
regex==2024.11.6
requests==2.32.3
rich==13.9.4
ruamel.yaml==0.18.10
ruamel.yaml.clib==0.2.12
safetensors==0.5.3
scikit-learn==1.6.1
scipy==1.15.2
semver==3.0.4
sentencepiece==0.2.0
setuptools==78.1.0
shellingham==1.5.4
six==1.17.0
sortedcontainers==2.4.0
soundfile==0.13.1
speechbrain==1.0.2
SQLAlchemy==2.0.40
sympy==1.13.3
tabulate==0.9.0
tensorboardX==2.6.2.2
threadpoolctl==3.6.0
tokenizers==0.21.1
torch==2.2.2+cpu
torch-audiomentations==0.12.0
torch_pitch_shift==1.2.5
torchaudio==2.2.2+cpu
torchmetrics==1.7.0
tqdm==4.67.1
transformers==4.50.3
typer==0.15.2
typing_extensions==4.13.0
tzdata==2025.2
urllib3==2.3.0
whisperx==3.3.1
yarl==1.18.3