Big Tech zuhause
Da ich in letzter Zeit bereits ein paar Beiträge zu WhisperX im Ökosystem Proxmox mit Container geschrieben habe, kommt dieses Mal Ollama dran. Was ist Ollama? Der defacto Standard für lokal betriebene Sprachmodelle (LLMs). Die Installation am eigenen Rechner ist relativ einfach, aber manchmal möchte man auch über den Server drauf zugreifen.
LXC Vorlagen nutzen
Diese Anleitung ist sehr detailliert und ich werde die Schritte darin befolgen. Aber zuerst erstelle ich noch einen Klon von von meinem GPU-LXC-Container:
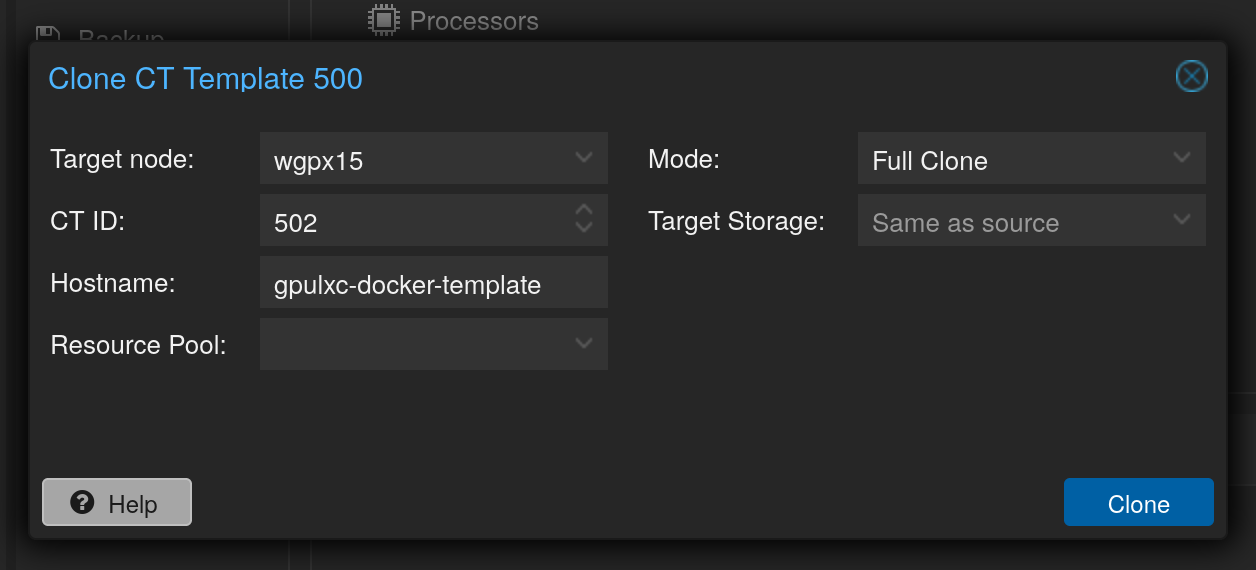
Auf diesem Klon kommt Docker und andere notwendigen Pakete/Programme und dann wird wieder ein Template daraus erstellt. Damit kann man für jedes kleine Projekt oder Vorhaben die richtige Vorlage wählen. Die ganzen Container (aktive und ver-templatisierte) werden dann auch noch auf den separaten Backupserver mit dem Proxmox Backup Server (PBS) gespielt.
Es ist auch empfehlenswert gleich einmal einen Snapshot zu erstellen – auch wenn dieser bei der Umwandlung in ein Template wieder gelöscht werden muss – denn falls beim Aufsetzen etwas schief geht, kann man komfortabel und innerhalb von Sekunden wieder zurück zum funktionalen Ausgangszustand (siehe hier).
Einrichtung des Container-Templates
Beginnen wir mit den Container-Tools:
apt install gpg curlDann Repo-gpgkey hinzufügen:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| tee /etc/apt/sources.list.d/nvidia-container-toolkit.listListe aktualisieren:
apt updateUnd Container Toolkit installieren:
apt install nvidia-container-toolkitJetzt config.toml anpassen…
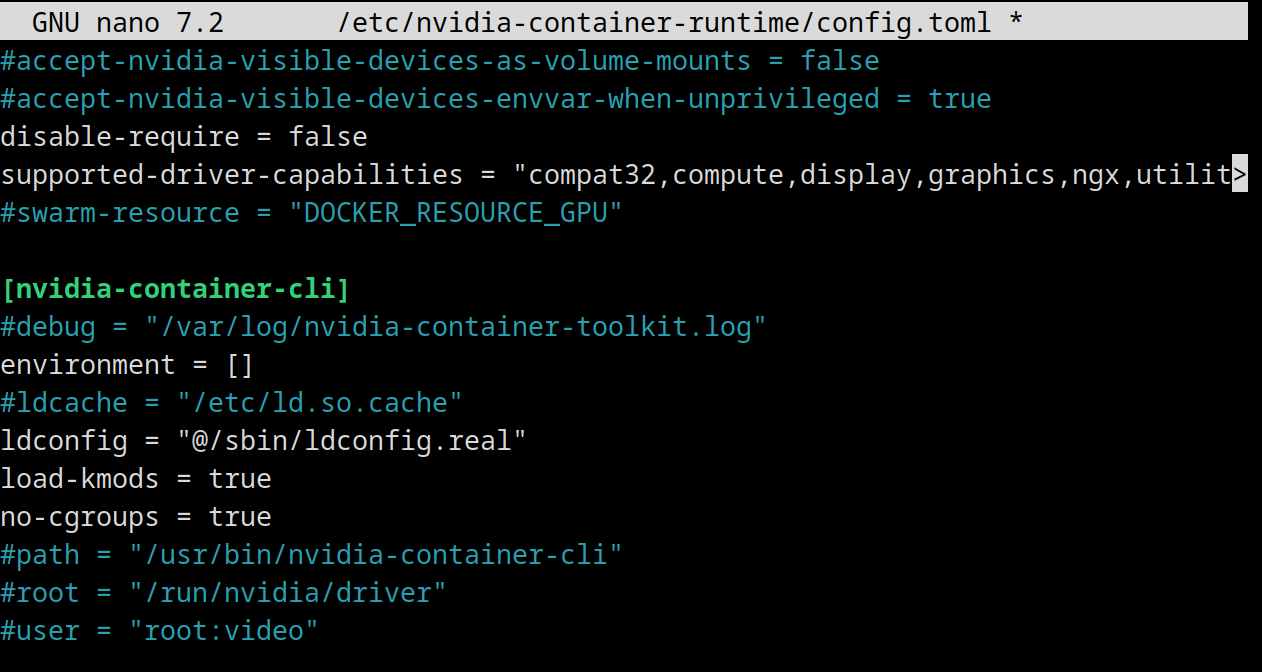
nano /etc/nvidia-container-runtime/config.toml… die Kommentierung bei #no-cgroups = false…
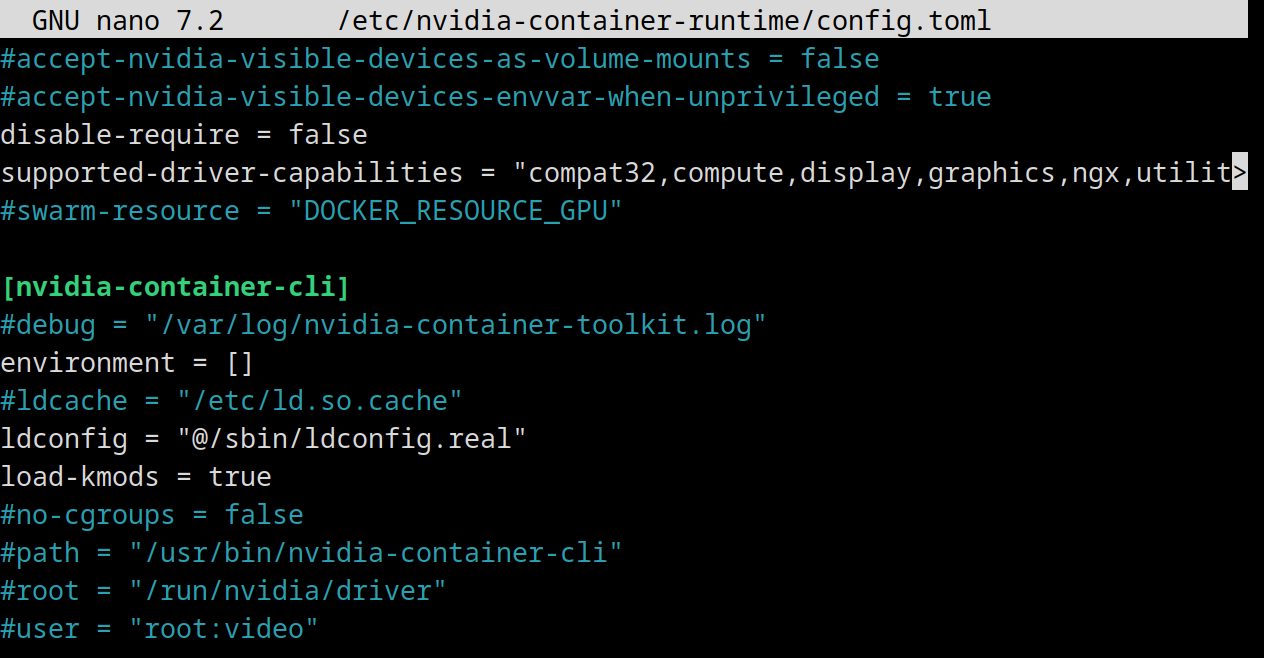
… entfernen und false durch true ersetzen:
Docker in LXC Container installieren
Wir verwenden Docker Container im LXC Container. Diese Verschachtelung ist zwar etwas kontrovers, viele raten davon ab und empfehlen eine eigene virtuelle Maschine für Docker. Nachdem man aber eine Consumer Grafikkarte üblicherweise nur einer virtuellen Maschine zuweisen kann, finde ich, dass die Vorteile eines LXC-plus-Docker-Ansatzes überwiegen. Denn so kann ich den GPU-Server einschalten und nach Belieben (wie gut das funktioniert möchte ich auch testen) verschiedene Services darauf zugreifen lassen. Bei einer VM muss man alles wieder in einer Umgebung haben. Wie auch immer zurück zur Installation.
Docker lässt sich recht einfach installieren, und dazu fügen wir abermals ein Repository hinzu. Es geht zwar auch mit Skript, aber das ist nicht so empfehlenswert. Eine Anleitung von mir dazu gibt es auch, aber auch die obige Anleitung hat die selben Schritte1 nur halt für Debian 12 und nicht Ubuntu 24.04 (kommen eh direkt von Docker selbst):
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get updateDann die Docker Pakete installieren:
apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-pluginNvidia Toolkit für Container aktivieren:
nvidia-ctk runtime configure --runtime=docker

Und Docker neustarten:
systemctl restart dockerJetzt sollte alles laufen und wir können wieder ein Template aus dem Container machen, bevor wir die nächsten Anwendungen installieren.
GPU-Docker-LXC Template erstellen, klonen und Ollama installieren
Zuerst Snapshot entfernen und dann Rechtsklick auf Container und “Convert to template” auswählen.
Als nächstes sofort wieder einen Container durch Klonen daraus erstellen und dann Service User erstellen und zur Docker Gruppe hinzufügen:
adduser gpuollamauser
usermod -aG docker gpuollamauser
Wenn es schnell gehen soll dann
Dann aus- und einloggen, damit die Änderung wirksam wird oder newgrp docker ausführen. Zum User wechseln…
su gpuollamauser
… und wenn es schnell gehen soll, dann einfach mit docker run den Docker Container mit Ollama starten:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaOder, meiner Meinung nach, etwas eleganter mit Docker Compose. Hier zuerst ins Home Verzeichnis wechseln, Ordner erstellen, dort reingehen…
cd /home/gpuollamauser
mkdir ollama
cd ollama
nano docker-compose.yml… und schließlich folgende Zeilen als docker-compose.yml speichern…
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- .ollama:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped… und mit docker compose up -d starten.
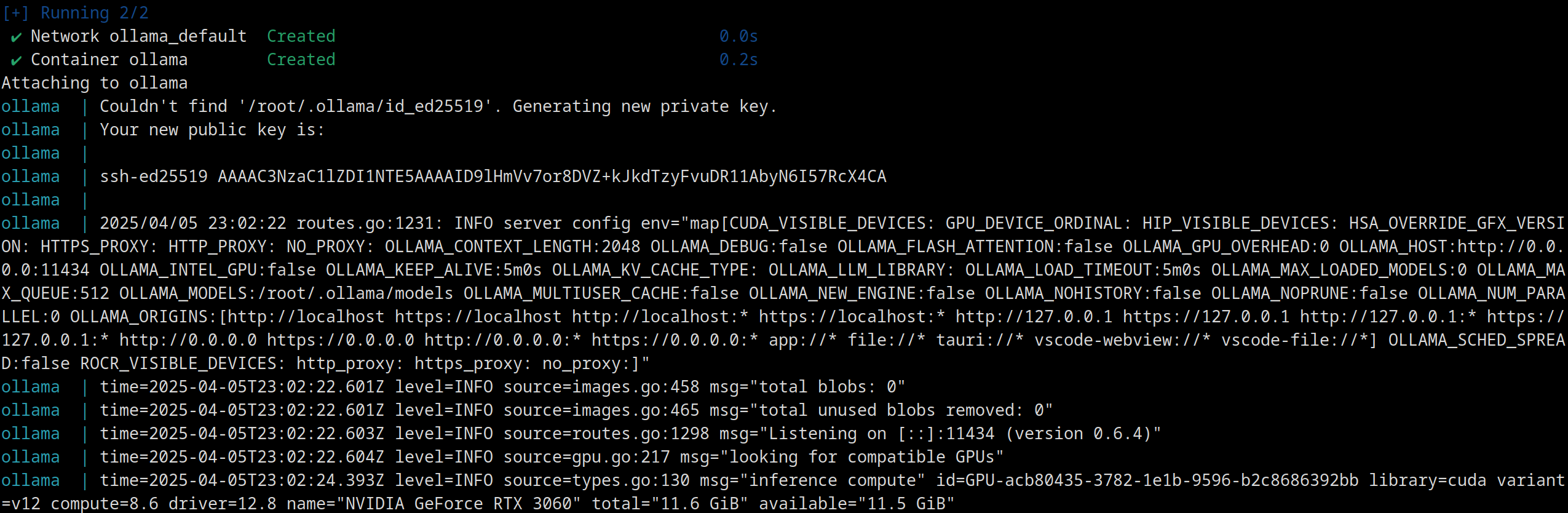
Das kann jetzt, je nach Internetverbindung, relativ lange dauern:
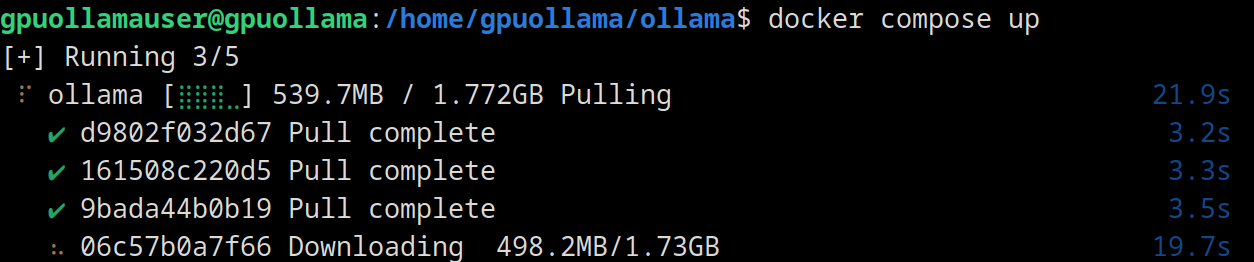
Aber keine Sorge, die Sprachmodelle selbst sind eh noch einmal um ein Hauseck größer. Das muss ich auch noch bedenken, dass der Container zurzeit ja nur 32 GB Speicherplatz hat. Vielleicht sollte ich den LLM-Cache als Netzlaufwerk oder Blockdevice in den Container einbinden?
Ich habe dazu einmal LeChat probiert um nicht die ganze Zeit nur nordamerikanische oder chinesische Sprachmodelle zu verwenden. Die Antwort ist etwas generisch:
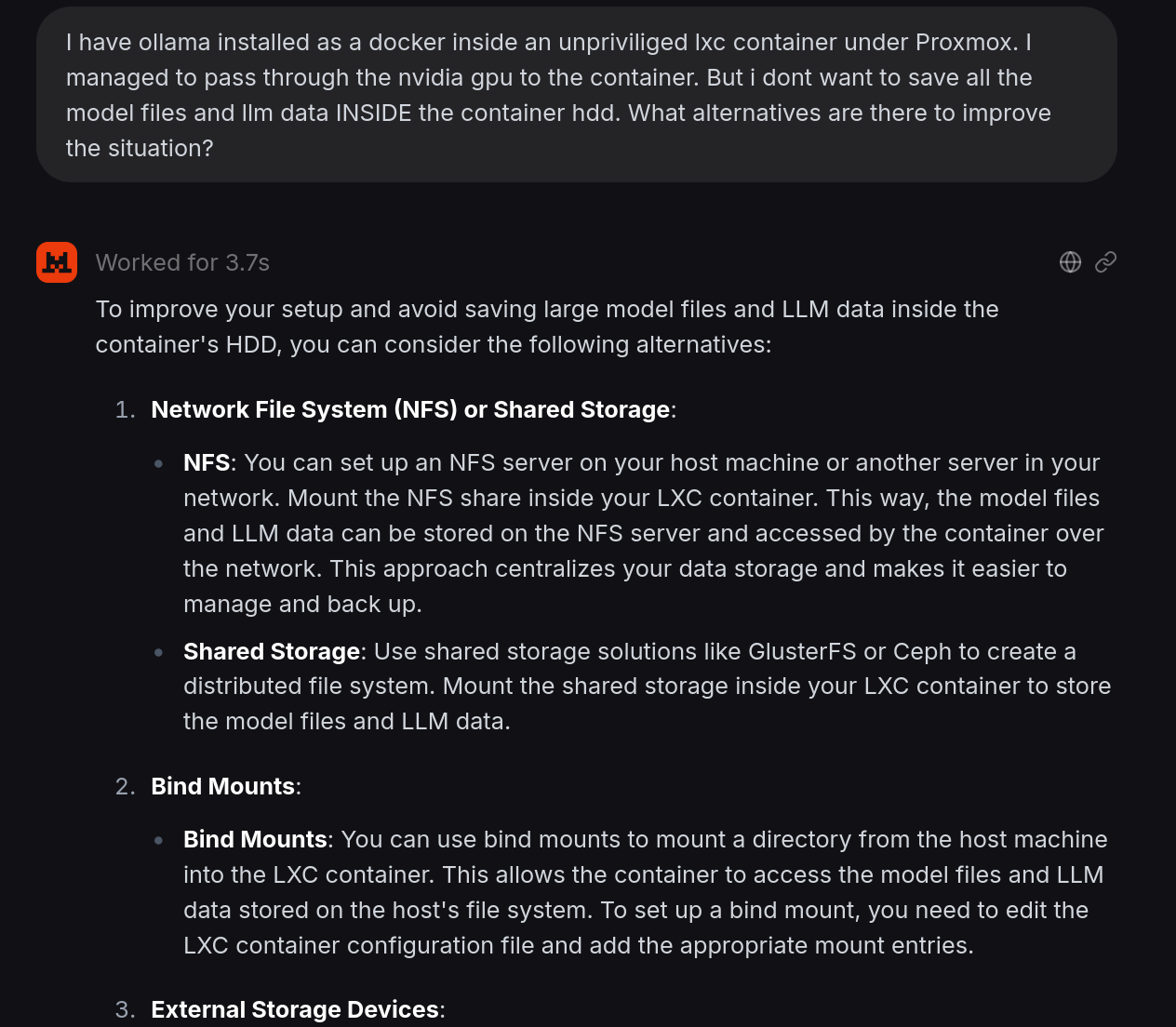
Auf NFS bin ich eh selbst gekommen, aber was der Chatbot hier nicht schreibt, ist, dass bei unprivilegierten LXCs (und das erwähne ich im Prompt auch) man keine Netzwerkshares einfach so einhängen kann. Wenn ich seinem Rat folge, kommt danach sicher irgendeine Entschuldung über die Verwirrung… Oder vielleicht auch nicht, vielleicht tut der französische Chatbot da etwas anderes? Probieren wir mal:
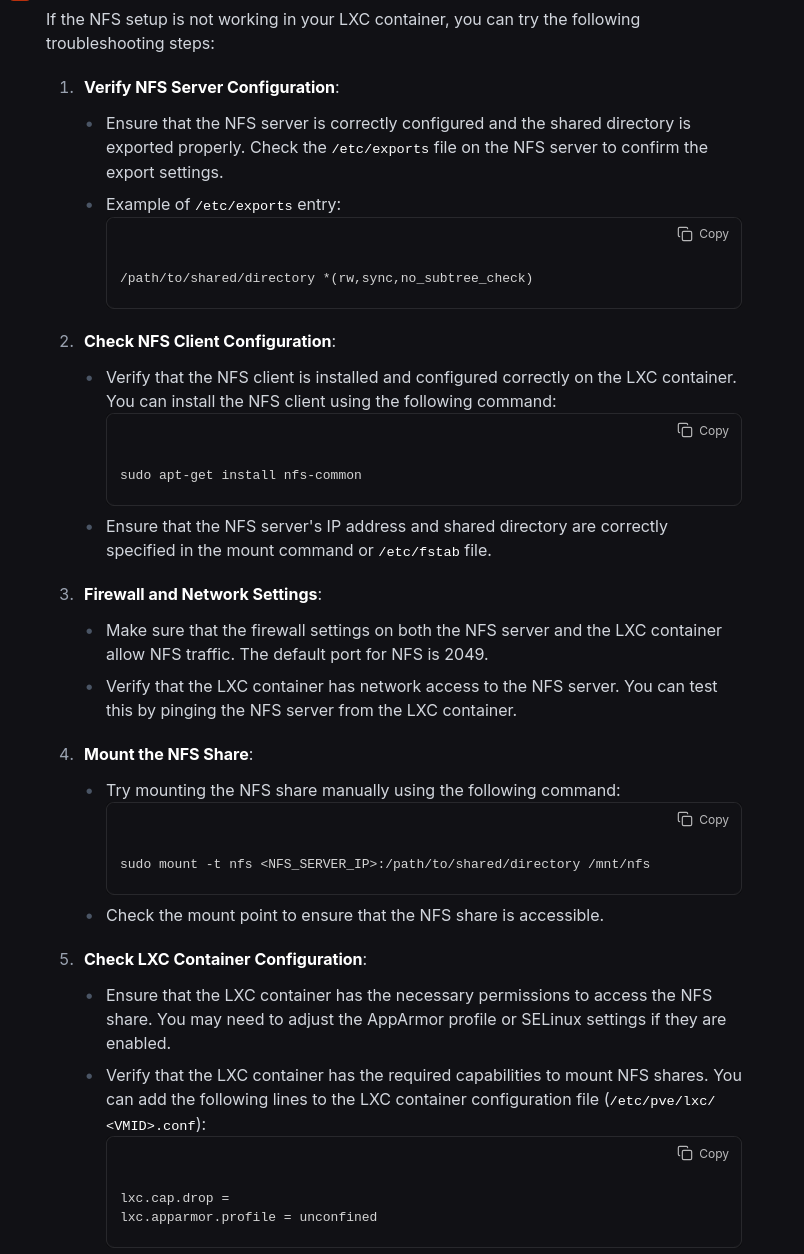 Naja, erst Punkt Nr. 5 spricht das Problem etwas an. Egal, zurück zu Ollama, das hat schon einmal funktioniert:
Naja, erst Punkt Nr. 5 spricht das Problem etwas an. Egal, zurück zu Ollama, das hat schon einmal funktioniert:
Zum Testen verwende ich OpenWebUI, welches ich bereits mit einem Community Skript installiert habe. Dort tragt man die IP-Adresse vom neuen Container ein:
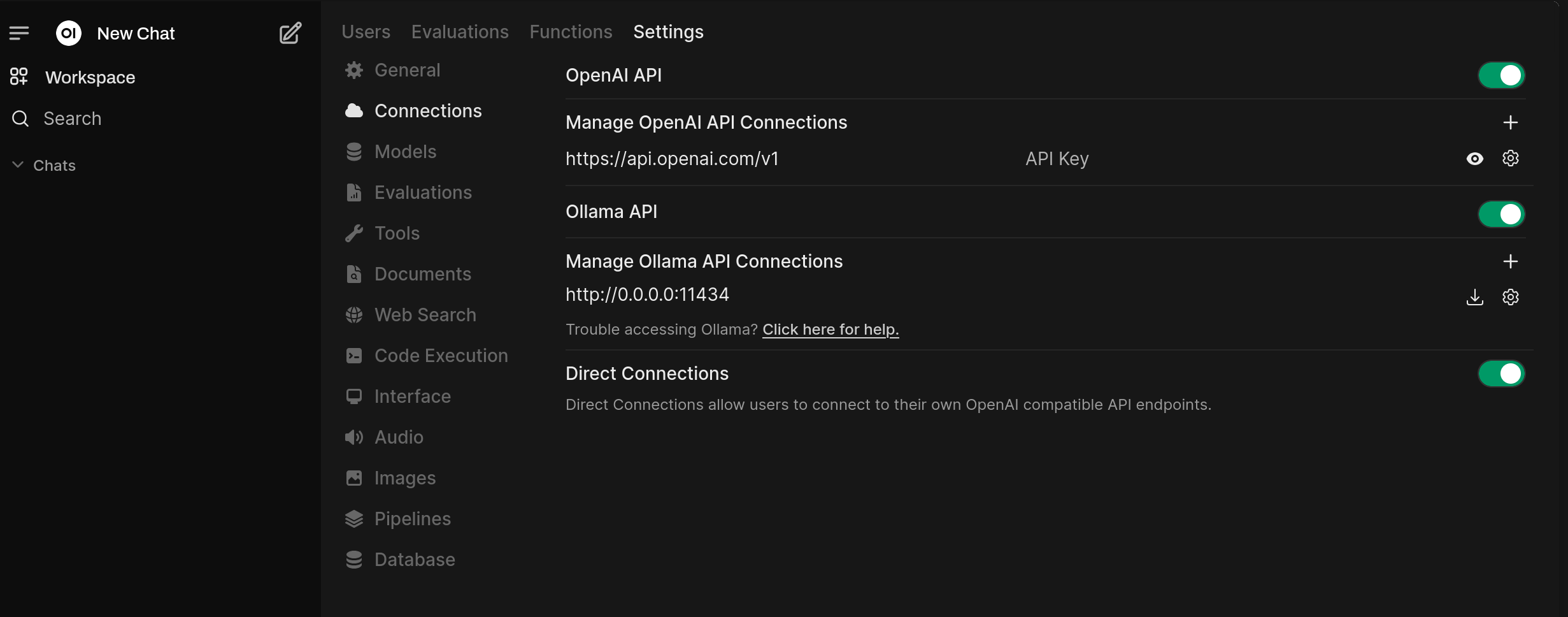
Probieren wir gemma3 mit 12 Milliarden Parameter aus:
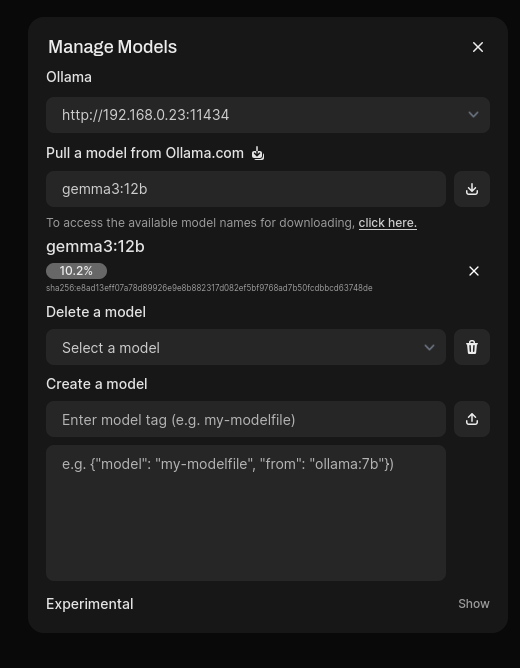
Laut Beschreibung derzeit das beste Ein-Grafikkarten-Modell. Und?
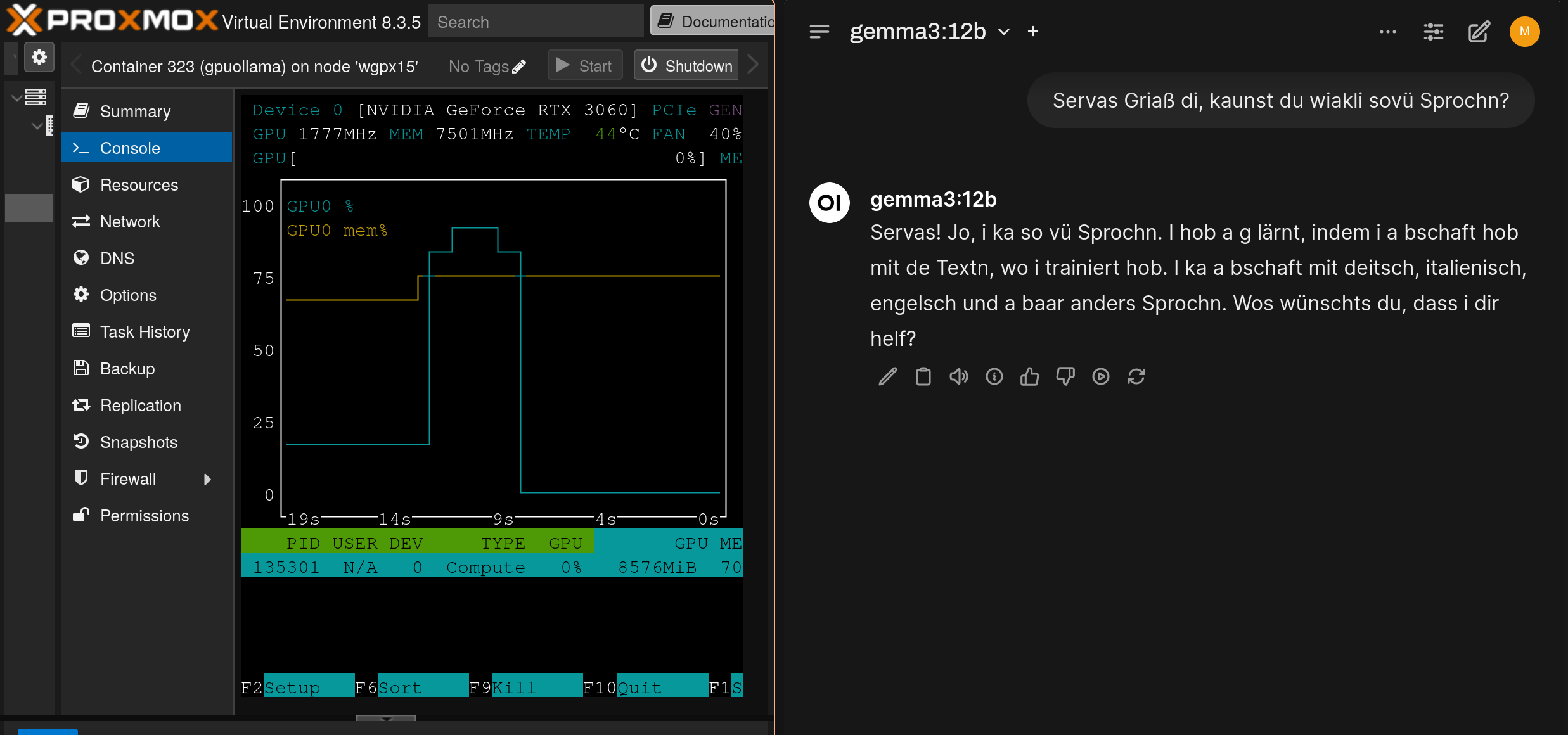
Naja, es ist ein Dialekt, aber welcher ist mir etwas unklar. Aber beeindruckend für so ein relativ kleines Modell.
Fazit
Mit einer relativ günstigen Grafikkarte kann man unter Proxmox seinen eigenen Chatbot-service einrichten. Hoffentlich kann diese kleine Anleitung für manche hilfreich sein.
Footnotes
-
Überprüfung ob es eh wirklich die selben Schritte sind (Zen-Browser mit Splitview):
 ↩
↩